A interpolação, trata-se do processo de ajuste de uma função matemática aos pontos de dados amostrais. Esse ajuste tem por objetivo a determinação de valores da variável de interesse em pontos não amostrados.
Os pontos de dados podem ser amostrados no plano, em área ou em volume, que definem a dimensão da interpolação em 1D, 2D e 3D, respectivamente. Exemplos de interpolação em 1D podem ser representados por medidas de uma variável em função de outra, como pressão em função da temperatura.
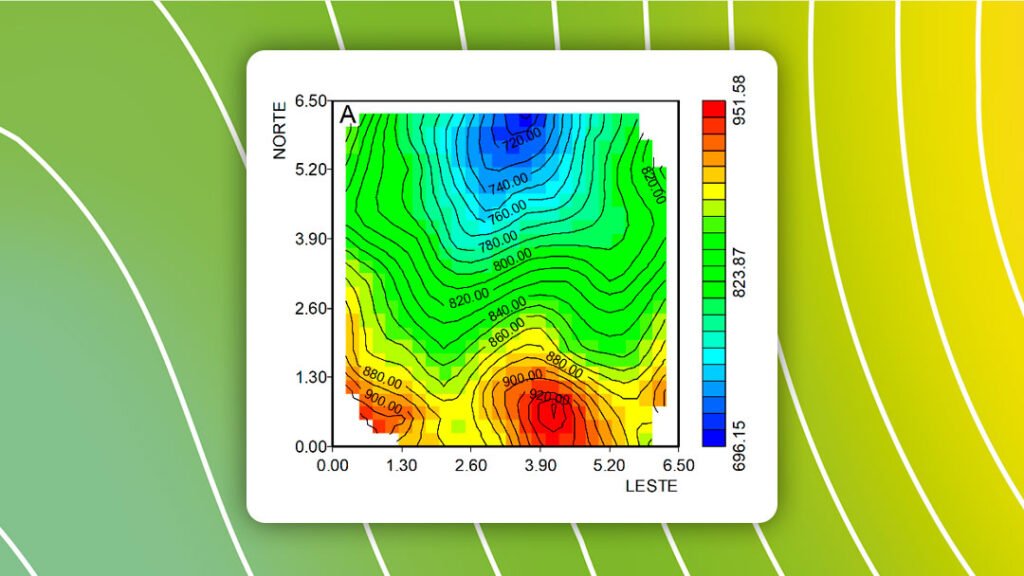
Em 2D, a partir dos pontos de dados distribuídos em área se procura obter o padrão de distribuição e variabilidade espaciais da variável de interesse. Por exemplo, em agricultura de precisão, tem-se os pontos amostrais (uma amostra por hectare) com determinação de K e se deseja obter o mapa de distribuição dos valores de K em toda a área investigada.
A partir deste mapa da distribuição espacial, pode-se calcular corretamente a dosagem de K necessária localmente. Em 3D, os pontos de dados amostrais são referenciados não apenas por meio de suas coordenadas geográficas, mas também por um terceira variável que é a cota do terreno ou profundidade, no caso de sondagens.
As aplicações mais comuns podem ser encontradas na investigação de sítios contaminados ou na exploração mineral, onde o depósito mineral é pesquisado por meio de sondagens rotativas.
Nesta série de artigos, vamos tratar dos métodos de interpolação 2D, devido à sua ampla aplicação nos mais diversos campos de estudo. Esses artigos serão baseados no Capítulo 6 – Métodos de interpolação de dados 2D – do livro “Estatística, análise e interpolação de dados geoespaciais”, deste Autor.
1 – Definição de uma Malha Regular
Geralmente, os métodos de interpolação são aplicados com o objetivo de se obter uma malha regular, em cujos nós os valores da variável de interesse são calculados.
Na verdade, a interpolação de uma malha regular é uma etapa mandatória na análise de dados espaciais, pois mesmo que a amostragem tenha sido planejada em uma malha regular, raramente se obtém as amostras exatamente nas localizações desejadas (Isaaks e Srivastava, 1989, p. 141).
As causas dessa impossibilidade estão geralmente associadas a acidentes geográficos, sejam naturais (rios, pântanos, lagos etc.) ou artificiais (residências, edifícios, obras civis, lixões etc.).
O primeiro passo para se fazer a interpolação de dados 2D consiste na definição de uma malha regular 2D ou modelo bidimensional de blocos (Figura 1).

Como mostra esta figura, as coordenadas mínima e máxima nos eixos X definem os limites da malha regular. As aberturas DX e DY são usadas para estabelecer o número de nós da malha regular, respectivamente nos eixos X e Y. Os pontos da malha regular podem ser dispostos nos nós da mesma ou nos centros das células (Figura 2).

Geralmente, os pontos são calculados sobre os nós da malha regular (Figura 2A) quando houver a necessidade de se obter um mapa interpolado da variável de interesse. Por outro lado, quando o objetivo for avaliar o teor ou o valor da variável dentro da célula, calcula-se o valor interpolado no centro da célula (Figura 2B).
O número de pontos no eixo X pode ser calculado como:

Referências Bibliográficas
Isaaks, E.H.; Srivastava, R.M. 1989, Applied geostatistics, New York, Oxford University Press. 561p.
Yamamoto, J.K. 2020. Estatística, análise e interpolação de dados geoespaciais. São Paulo, Gráfica Paulo’s. 308p.